How you can use DRS groups
As one of many the first thoughts when i heard of DRS groups was what should or could i do with this feature? I know of the DRS groups some time know but i have never seen it in production. Until now! For a customer i am working on en upgrade project of ESX 4 to ESXi 4.1 and the production environment is full and when i say full it is full because it is 114% in use and there is some latency noticeable. This is not the kind of situation that you want in your production environment. But the customer does not have the budget to buy additional hosts. The do have some extra host witch is equipped with a other process family. First thing i thought was lets put them in the same cluster and turn on EVC. But as you can see in the picture below this is not possible

So without buying extra server or hardware and wanting to expand the cluster to use HA in case of a host failure i put the host in one cluster and enabled Ha and DRS. Within the options of DRS a made two DRS Host groups for this cluster less say I original hosts and strange hosts. On the two strange hosts i put some virtual machines that are less important. Why less imported? In this case i spoke with the customer and gave him the scenario when a hosts failed and you must choose which virtual machines are les crucial for the business. Witch virtual machines would be the candidate to turn off in such situation.
As can be seen in the picture below i made a virtual machine group of virtual machines and called it less important. In this group i have add the less important virtual machines. I have also made a Host group named strange host and added the strange new host in this group.
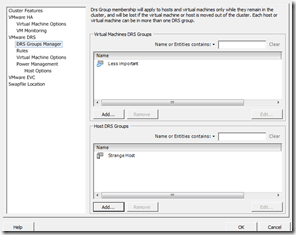
Picture of DRS group manager
In the picture below the rule that combines the two groups strange host and the less important virtual machines group.

![]()
When you combine these groups you must make a choice on how DRS must response. In this case i choose for the less important virtual machines to run only on the strange hosts and let the other virtual machines run on all hosts including the strange host. The following options are available

In this case i choose Must run on hosts in group. So what if;
The strange hosts fails the virtual machines in the group less important will stay down
When another host fails the virtual machine will continue to run (after HA has done his job) on the hosts that did not fail even on the strange hosts
In the case of the costumer the strange host has enough space to host some extra virtual machines. And he benefits of extra capacity in his cluster also when hardware fail. There is a N+1 solution now.
The drawback is that he cannot make benefit of the extra capacity when virtual machines want to use more resources because vMotion will not work between the exciting hosts and the new strange host. there is the second drawback because when the host recovers then VM’s must be turned down to move to the correct host if they are started on one of the strange hosts. This is not the most ideal (or recommended) situation but for know the customer is out of the danger zone!
Was once an enthusiastic PepperByte employee but is now working elsewhere. His blogs are still valuable to us and we hope to you too.